magi搜索__一个别样的知识搜索引擎
正文:
今日,给大家推荐款知识图谱的搜索引擎,magi搜索(点击访问magi搜索), 接下来我们会通过以下五个部分进行讲述:
- 为什么会向大家推荐这款产品?
- magi搜索简介
- magi核心技术
- 创始人NB!
- 从个人角度,提出一些建议和意见。
- magi对未来的产品,究竟意味着什么?
1. 为什么会想大家推荐这款产品
这个产品是通过微信公众号看到的,看完全文后,就迫不及待的体验产品,并查看了作者相关的博客、知乎等,哇哦,体验下来很牛的样子。
这款产品,除了讨论一下技术层面的厉害之处,创始人令人敬佩之处外,还想再深入的和大家探讨一下关于AI对未来产品的影响。
我也在AI这个行业做产品经理约5年,但真正的,把AI做到如此纯粹的公司也是少数,它的精彩之处,除了产品以外,还启迪了我们对于未来AI产品形态,AI场景的一些思考(小编的心,鸡冻鸡冻)。话不多说,让我们进入正题。
2. magi搜索简介
2.1. magi搜索首页
下图就是首页的截图(小编很想搞一个GIF,可惜还没有学会相关技术,哭哭o(╥﹏╥)o)
输入
经过试验,我们可以输入以下几种内容
- 关键词,”知识图谱”
- 问题,”985的学校有哪些”
- 表达式,”3+5”
其他
我们还可以看到目前magi正在学习的文章标题、链接,以及学习到的内容。将AI过程可视化,让用户真正的信服你的产品,相信技术,真的是AI产品必修的一门课呀
2.2. magi搜索结果页
从页面上看,结果分为4个模块:
- 搜索框
- 结构化数据
- 主要学习来源
- 相关报道(普通搜索引擎类似)
搜索框以及相关报道,我们其实已经很熟悉了,在其他产品中较为常见,我们主要就结构化数据以及主要学习来源来做一些。
我们可以从下图看到相关的结构化的数据的含义。
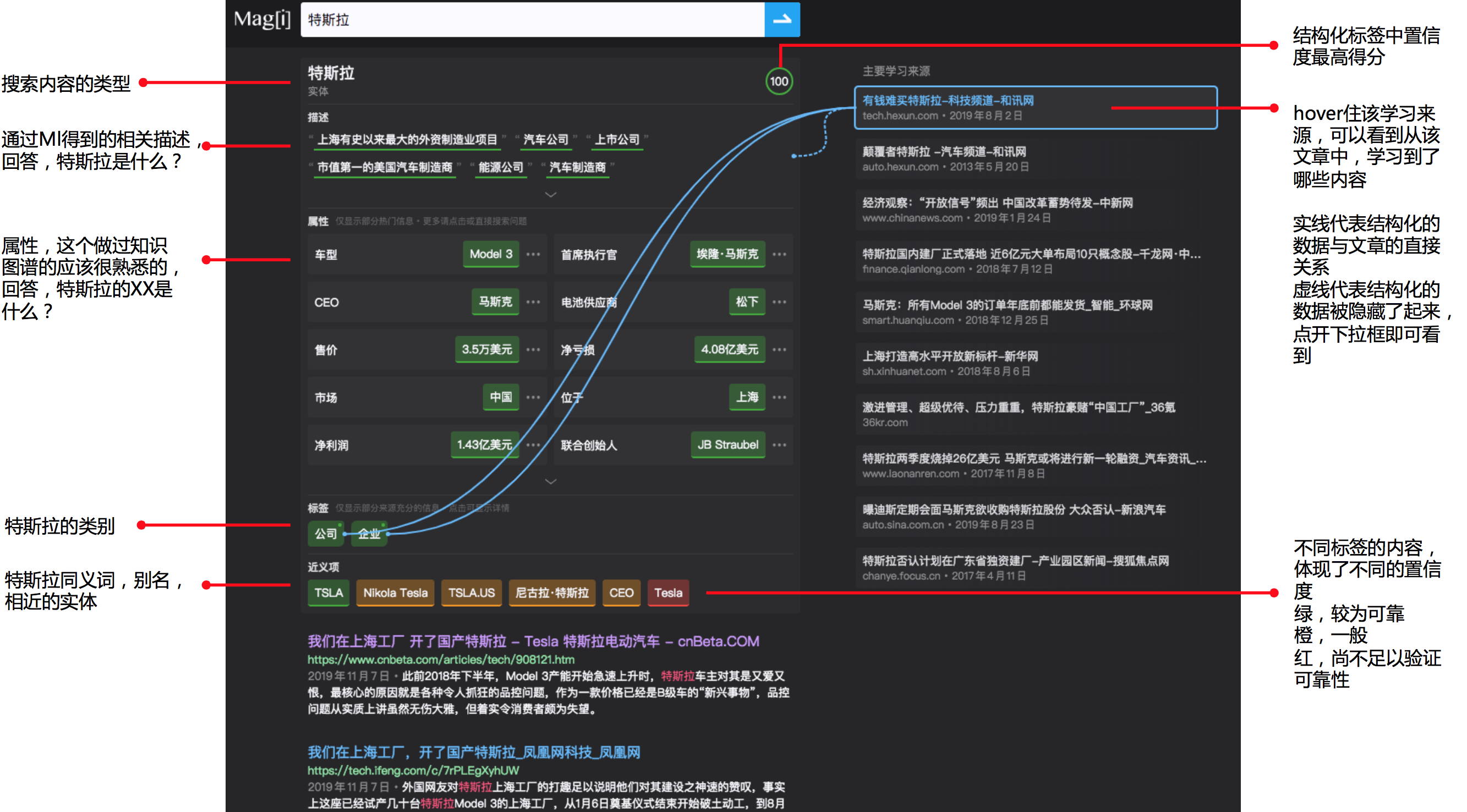
这里的所有带颜色框的标签,都是可点的,点进去后会出来,该数据的来源,以及置信度数值,当然此时hover住右端的主要学习来源还是有连线的。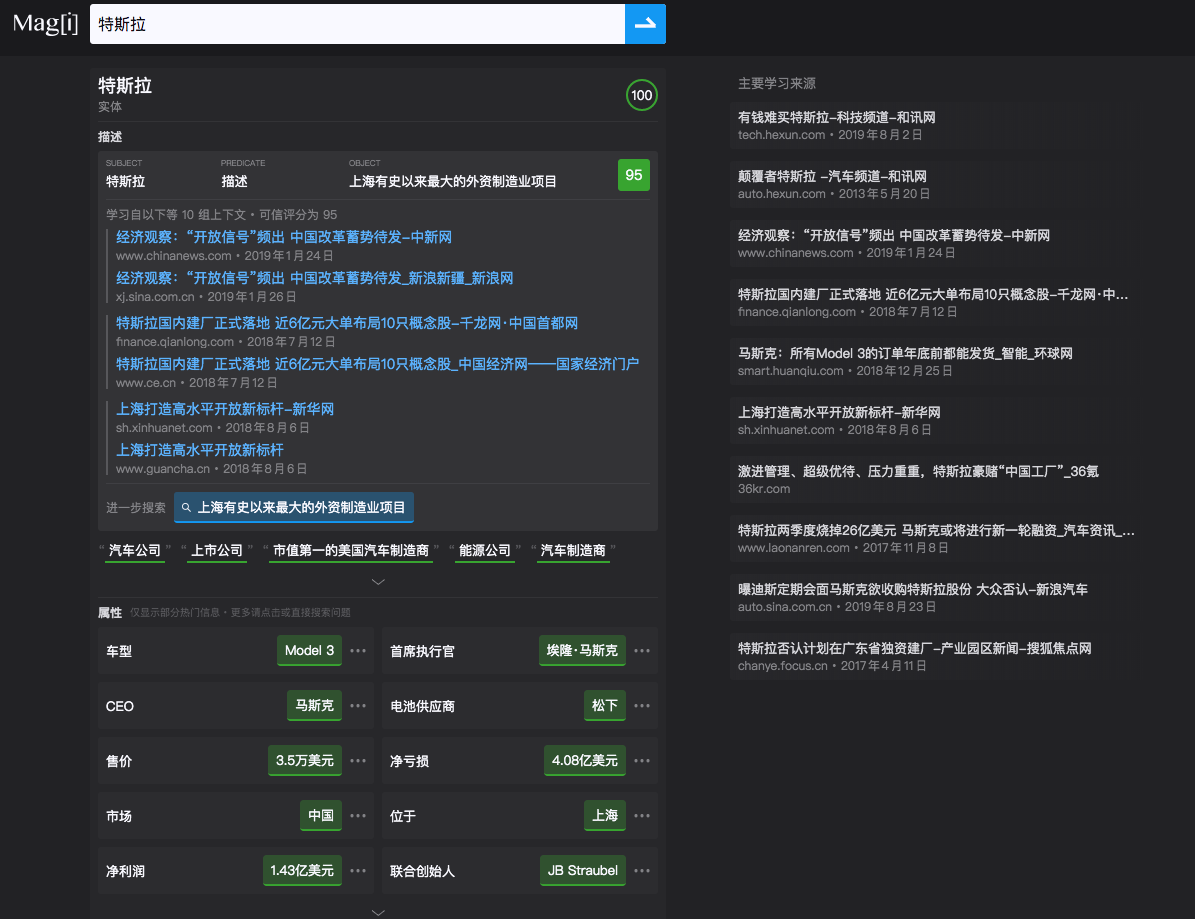
到这里,magi的搜索产品就介绍完了,很简单,就两个页面。其实很明显,这完全就是一个技术驱动的产品,那么我们接下来介绍一下他的一些技术。
3. magi核心
想看更详细的技术解析,大家可以访问面向硬核用户的问题与解答,知乎CEO官方回答,我们呢,就简单的讲讲。
搜索的过程分为以下几步:
- 意图识别
- 检索
- 排序
但我们这一次不讲这三步相关的内容,是不是很惊喜很意外,如果大家感兴趣的话,可以看小编的另一个篇文章,搜索是怎么样的一回事?。我们本次主要讲的是信息抽取的技术。
大家可以看到,搜索页面的结构化数据,和知识图谱是不是很像呀,数据结构都是三元组的形式。目前通常意义上的知识图谱都是全部人工,或者半机器半人工(人工确认)的方式来获取数据的。但是,magi太棒了,它可以通过文章,自动学习实体,以及实体与实体的关系。大家想详细的了解技术,就看一看上面的链接。能做到自动发现,且准确率较高,这本身就是一件很难的事情。
大家可以想象,如果有一天机器把这个世界各个角度,所有发生的事情都理解了一遍,那么它是不是就是某种程度的”上帝”了呢?如果知识图谱可以自动发现并积累各个领域的知识,那么无论是对于Siri、小爱同学,甚至对现有的模型及应用场景都是一个大幅的提升,远超人类也并非不可能。
正如创始人所说,这样其实也会面临以下几个问题:
- 消歧义的问题,如何把握这个度量,可以较为显著的区分不同含义的同一词组,比如”tesla”是一个人还是一个汽车品牌
- 工程上,在速度和成本方面还是有提升空间的
那有些朋友会问了:
万一magi去爬了某些质量不高的网站,或者抽取的信息错误怎么办?
- magi会评估每个来源的网站。为什么不用白名单来解决,因为白名单虽然可以保证质量,却也失去了很多内容。
- 由于magi每分钟都在学习新的知识,因此,在大量数据的情况下,被抽取错误的信息会慢慢变得正确。
4. 创始人NB
季逸超是北大毕业,Peak Labs创始人,猛犸浏览器,Magi智能搜索引擎的开发者。在19岁时便登上了《福布斯》杂志的封面。(大神就是从小不凡)
Peak Labs,已经获得红杉中国和徐小平创办的真格基金的天使投资。季逸超在自己的微博上说过,这个实验室“要做最狂最新鲜的事”。
创始人的知乎介绍:
5. 从个人角度,提出一些建议和意见
小编主要是做AI产品的,大部分会从页面上,小部分从算法结果上,给一些小小的建议,。
整体上来看,这是一个很geek的产品,产品设计页面展示上也是如此。
5.1. 页面上
- 目前置信度是通过颜色来表示的,如果没有人阅读过相关文章的话,很难第一眼就发现颜色的含义。建议:通过引导页,或者直接不用颜色,用文字的方式进行展示区分;
- 任何标签都是可点击,点击后才知道,可做引导页提示;
- 属性后的…是可以同时搜索的,输入框的条件以及目前点击的实体的组合,这个一般用户尝试过后才能知道,产品上可做的稍微明显一些;
- 标签右上方的小绿点,嗯,小编不知道,这个是啥意思,还没理解;
- 在描述和属性中,我们可以看到很多相关的内容,是否在展示的时候,可以把相关的展示到一个模块,比如上市公司,那就把公司财报相关的数据放一起,目前看起来是有些乱的。根据一些维度进行区分后,不仅仅能解决乱的问题,还可以解决歧义的问题,比如”tesla”享年会和公司明显分区开来。
5.2. 算法结果上
- 同义词的结果仅展示一次即可。比如特斯拉的描述,”上海有史以来最大的外资制造业项目”和”上海有史以来最大的外商独资制造业项目”;
- 同义词的实体,比如搜索”特斯拉”,它是一个品牌,一家公司,但对应的实体就是一个,因此只需要出这个的相关信息即可,目前是有”特斯拉”以及”特斯拉公司”,且”特斯拉公司”的数据几乎没什么内容;另外”tesla”与”特斯拉”出来结构化的内容也是不同的;
- 某些无意义的词语。比如特斯拉的标签”项目”。


5.3. 展望
- 数据,关系的可视化,更炫酷的页面
- 更干净,更有层级的数据
6. magi对未来的产品,究竟意味着什么?
让我们从小入手,就从magi的核心,信息抽取来开始讲起。
信息抽取是NLP重要的一个组成部分,是NLP的基础工程。NLP的基础就是文本,我们从最小组合说起,句子。我们来思考下,句子的构成。将实体、关系通过一些助词、语法结构等,组合在一起,就是一个句子。将诸多句子组合在一起,就是段落,于是可称为文章。由此可看出,一句话的核心,就是实体和关系。我们一般通过NER、依存分析等等相关技术,来试图理解每一句话在讲什么意思,究竟是什么意思,有哪些实体,有哪些词语,有哪些关系,这些技术一般都需要人的帮助,且无法适用所有情景。
信息被结构化后,又有什么样的好处呢?
小编目前的领域是在做候选人与职位的匹配,我深刻的从实践中了解到,匹配精准的基础就是对两方的精准理解,当然,如果你的数据量大到不可思议,且分布较为均匀,嗯,当我没说。
- 为决策提供准确的基础数据,提高匹配的准确性,适用于推荐、匹配;
- 提高检索的有效性,直击答案,而不用人再次辨别,适用于搜索、对话系统;
- 可视化AI决策过程,适用于建立AI与人的信任度。
最后,magi技术的突破是否能像Deepmind的强化学习一样,引起AI领域的一阵海啸,我们拭目以待。