适合AI产品经理阅读的算法集合之KNN算法
正文:
KNN算法,k-NearestNeighbor,基本上就是,某一个样本可以用它最近的K个样本来表示。
该算法需要一份标准集,但不需要模型训练,就可以直接计算。
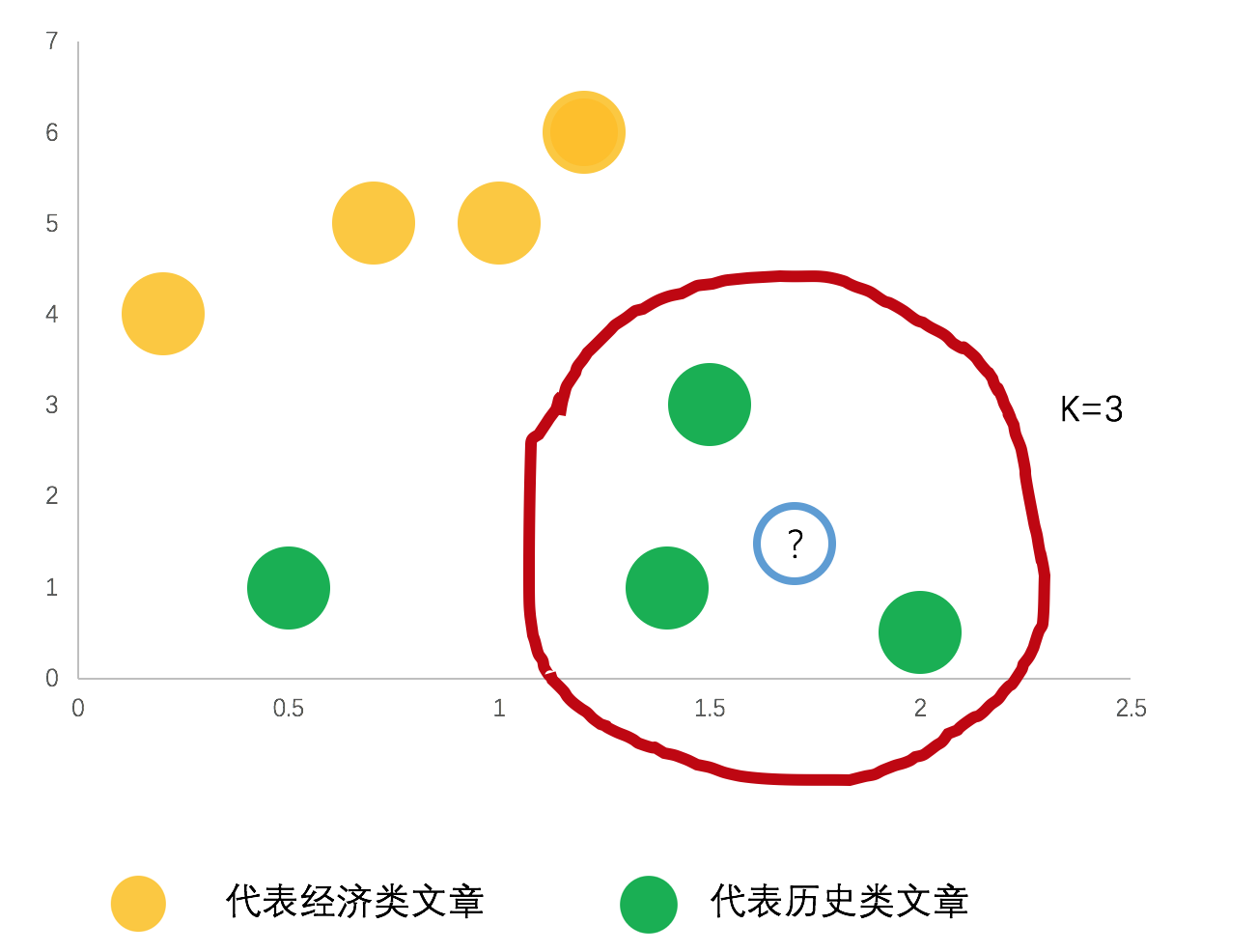
我们来举个例子,下图中有两个分类,那么?的数据应该是哪一类呢,我们取距离它最近的K个样本,K=3,发现他的分类应该是历史类文章。大家也可以想一下,如果K=4,5,6…会发生什么样的事情
KNN算法步骤
上述的例子中,就体现了KNN的整个算法流程,我们这边来总结一下相关步骤

- step1:标准集就是标注集,一份正确的样本及对应的分类;
- step2:特征建立,这是所有的算法模型都必须进行的步骤,此处不细讲,会有专门的文章讲述,简单来说,就是需要把认为重要的因素,把它数字化,比如把文本通过word2vec变成向量;
- step3:计算距离进行预测,距离的计算方式有欧氏距离、余弦距离、汉明距离、曼哈顿距离等;
- step4:确定K值,如上案例,如果K过大/过小,结果就会不一样;
- step5:计算分类标签,一般采用多数表决,可直接计算频次,取最高。
KNN算法优化
其实在上述步骤中,KNN的优化,也随之清楚
- 对应step1:尽量数据准确、分布均匀的标准集;
- 对应step2:建立优秀的特征数据;
- 对应step3:采用合适的距离测算方案;
- 对应step4:优化K值,可多做实验,找出最佳值
- 对应step5:计算方式,可算频次,也可加权,比如根据距离的远近
KNN算法局限
数据/特征大的话,计算量过大,时间较长,KNN适用于样本容量比较大的类域的自动分类。
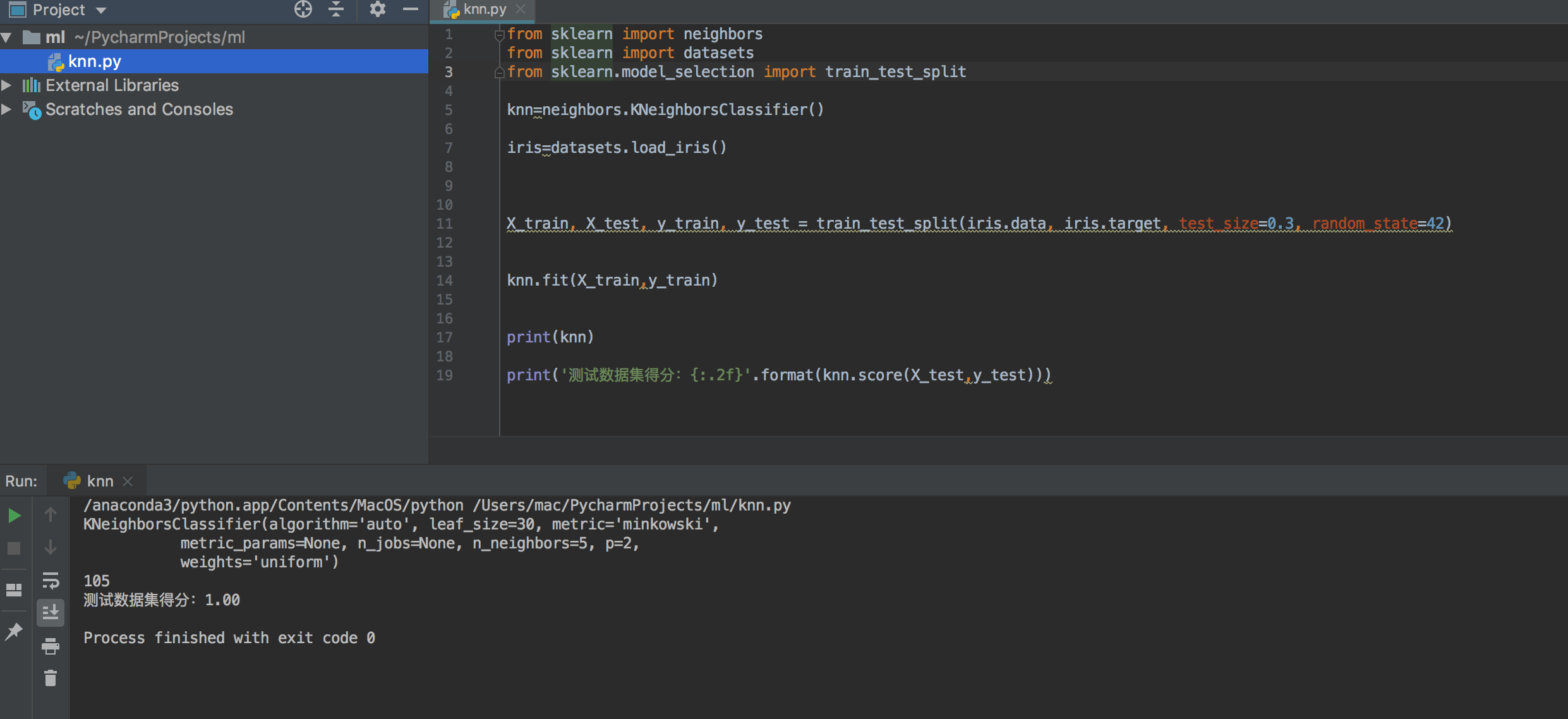
KNN算法实现
#适合AI产品经理阅读的算法集合系列。 该系列文章,主旨在于,用非技术性的语言,向大家介绍算法相关的模型和思路,让大家看的懂,听得懂。